Multi-Robot Navigation Under Uncertainty
This post dives into an approach, presented in my paper [1], that combines classical planning techniques and learning to guide a team of robots to reach unseen point goal in minimum expected distance..
Imagine a scenario where a team of multiple robots are deployed to rescue a victim in a burning office building. The robot team roughly knows where the victim is based on reports from survivors, but they don’t have a detailed map of the building. Equipped with cameras and LIDAR sensors to detect their surroundings, the robots need to navigate the unknown building to quickly reach the victim. However, without a known map, the fastest route to their goal isn’t clear.
One approach is what’s known as optimistic planning strategy. Under this approach, the robots make an optimistic assumption: they treat all unseen areas as free, unobstructed space and plan together to reach the goal, follow the plan, and make adjustments as the map is revealed.
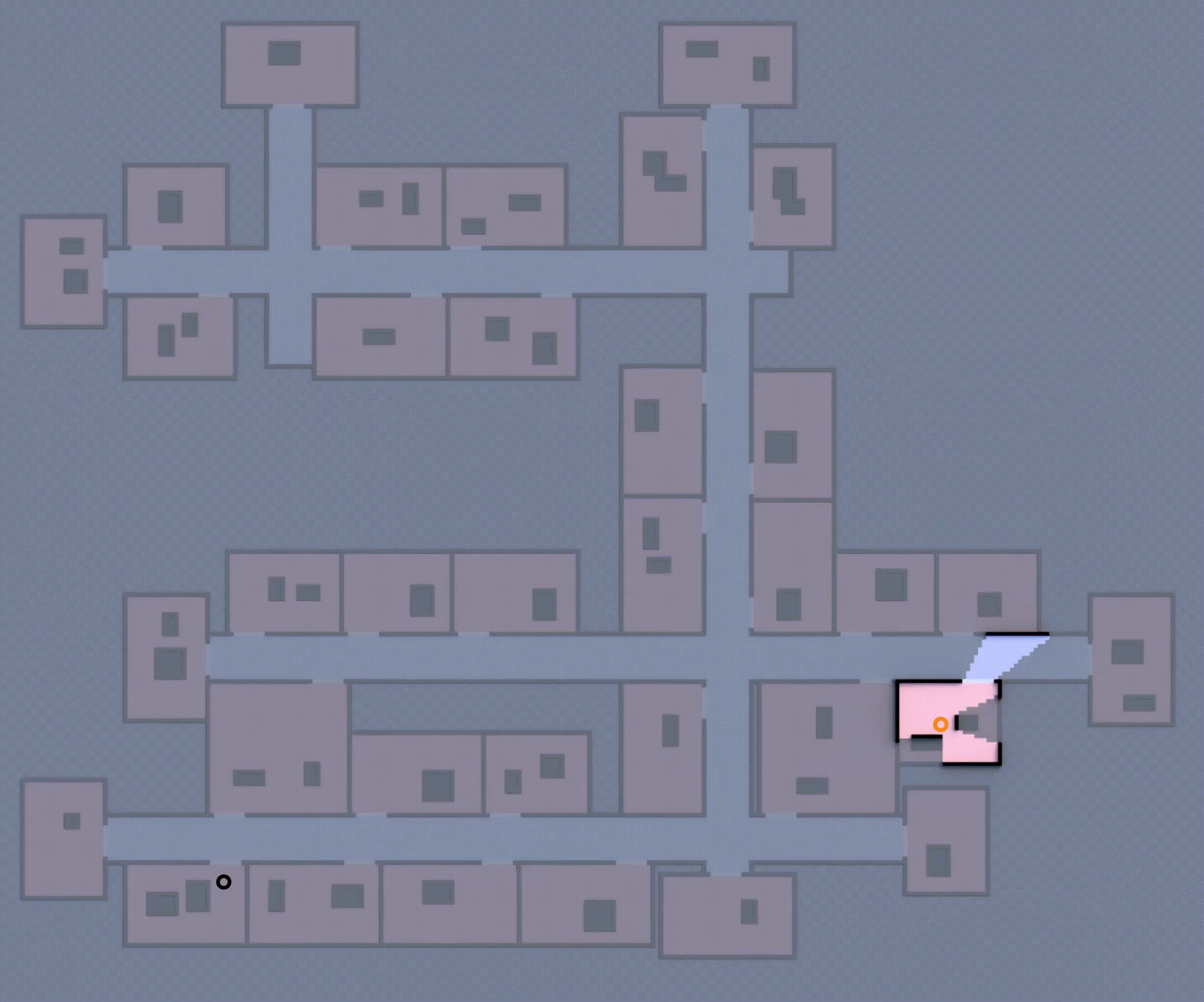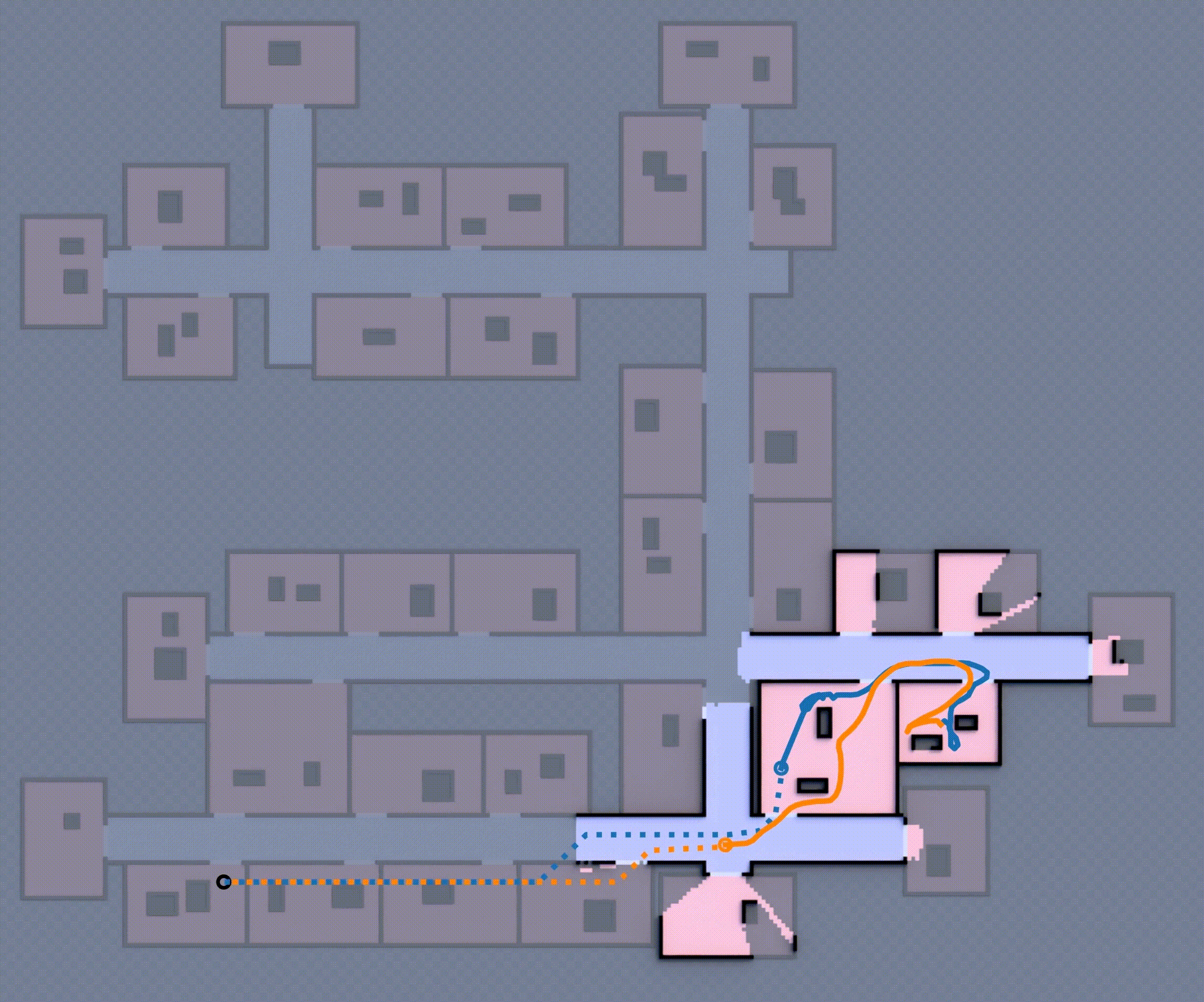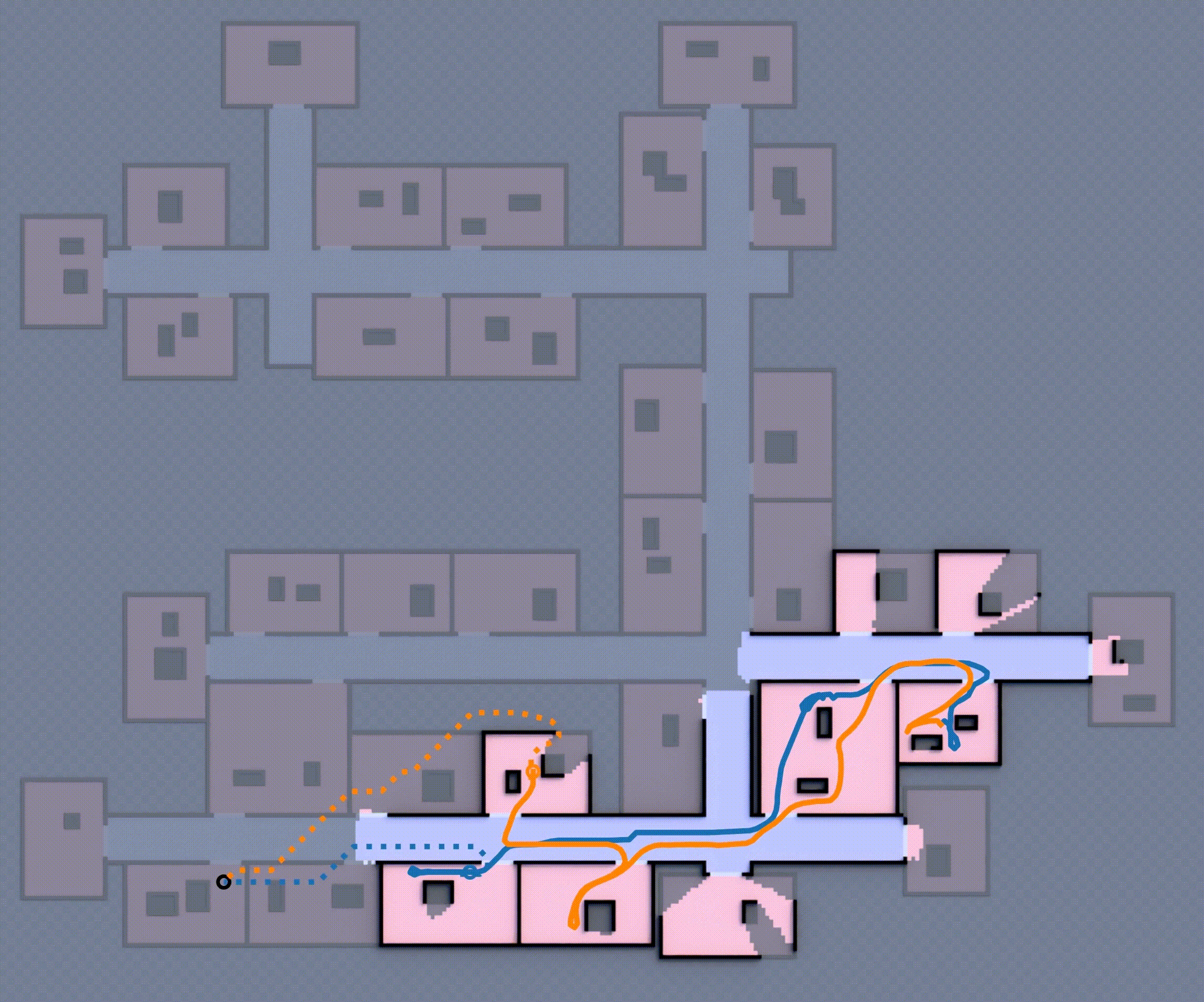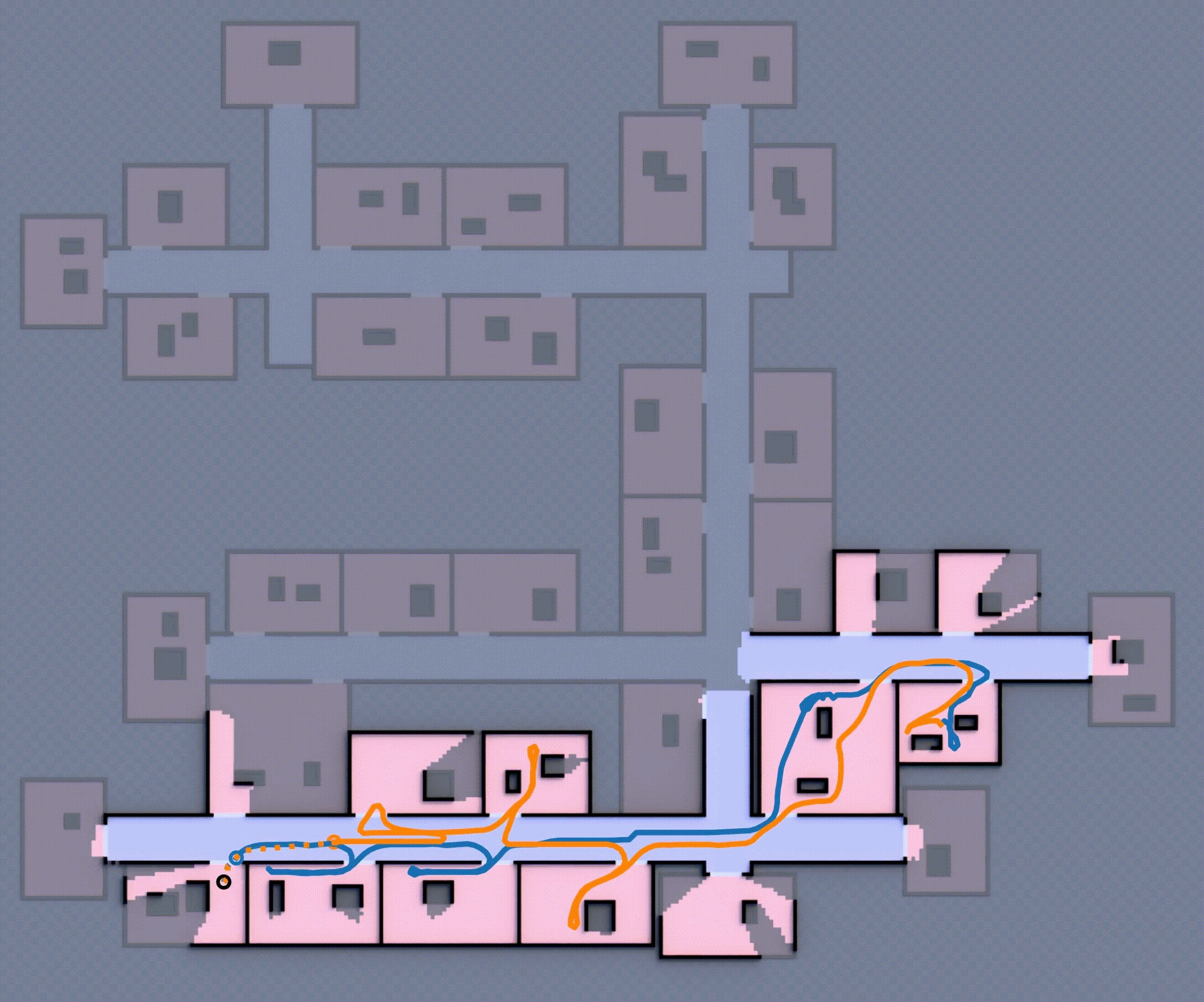
Although this approach is complete (i.e., the robot team eventually reaches the goal), the robot will repeatedly encounter unexpected obstacles, going inside rooms, often forcing it to backtrack and re-route to reach the goal as shown in Fig 1, which is ineffective. How can these robots effectively expore such unfamiliar environments, avoid dead-ends, and reach the goal in minimum expected distance?
Multi-Robot Learning Over Subgoals Planning (MR-LSP): using learning with classical planning for long-horizon deicison making
Instead of using optimistic planning, where robots assume every unexplored area is unoccupied, they can make smarter decisions by inferring what might lie in the unseen space. This is similar to how a human would act in a large building while searching for the nearest exist. Rather than checking every room, a person uses their prior experience to stick to the hallway, knowing that exits are usually located there, not inside individual rooms. To this end, MR-LSP leverages learning to estimate what lies in the unseen space with classical planning allowing multiple robots to coordinate and explore unknown areas to find unseen goal efficiently.
MR-LSP abstract both the state of the environment and the robot team’s actions to enable planning utilizing learning. High-level joint-action ($a_t$) for the robot team involve assigning each robot a subgoal—boundary between free and unseen space—to navigate towards and explore beyond in an effort to reach the goal.
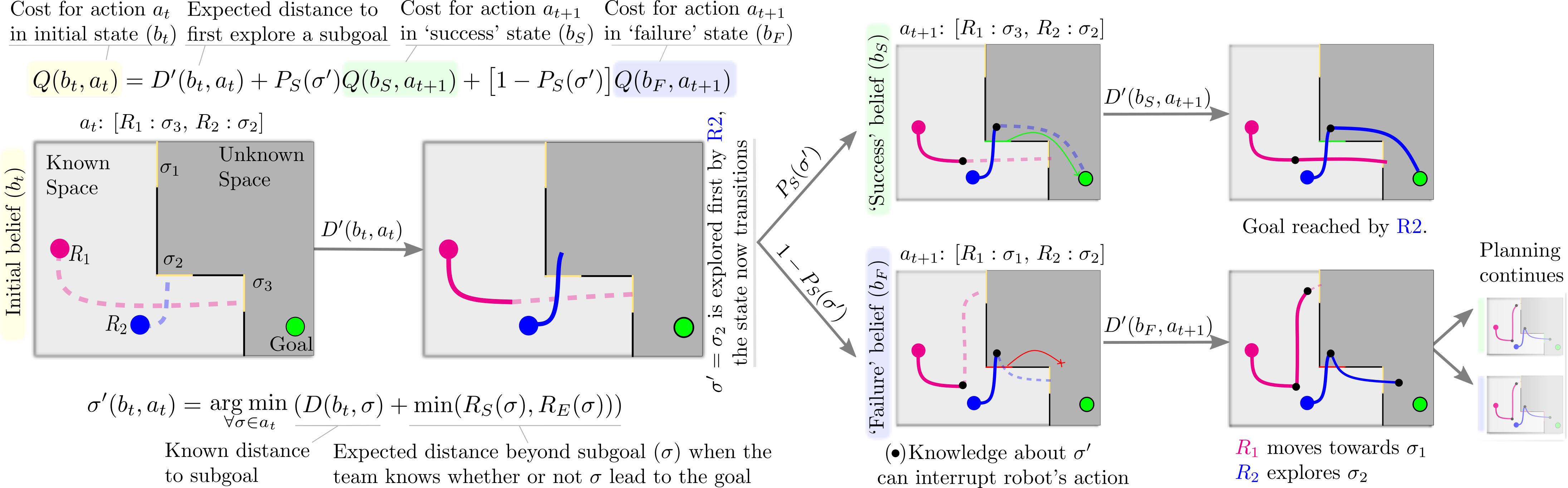
For each subgoal, learning estimates their properties: the likelihood of success $P_S(\sigma)$, the likelihood subgoal $\sigma$ leads to the goal; the success cost $R_S(\sigma)$, the expected cost in distance to reach the goal if that subgoal leads to the goal; and the exploration cost $R_E(\sigma)$, the cost of exploring that subgoal and coming back. The planning process for MR-LSP using high-level state and action is shown in Fig 2.
To compute the cost of a joint multi-robot action $a_t = [\sigma_2, \sigma_3]$, where $\sigma_2$ and $\sigma_3$ are the subgoal assigned to two robots, each robot makes progress towards their respective subgoal until a distance $D’$, when one (blue robot) discovers whether its subgoal $\sigma_2$ leads to the goal. Note that this $D’$ is the sum of cost for robot to reach the subgoal in known space, and expected cost in which the robot knows whether the subgoal leads to the goal. With probability $P_S(\sigma_2)$ the state transitions to a success state $b_S$ in which that subgoal is known to lead to the goal or, with probability $1 – P_S(\sigma_2)$ the state transitions to a failure state $b_F$ in which it is known to be a dead end. Planning proceeds from each of these new states with remaining subgoals as ${\sigma_1, \sigma_3}$ until all actions are exhausted.
Using this planning, and learned estimates from a CNN network, we can see that our robot team now divides effort thinking of long-horizon impact of their decisions, and uses learning to predict spaces that might lead to dead-end and avoid those spaces to reach the goal efficiently.
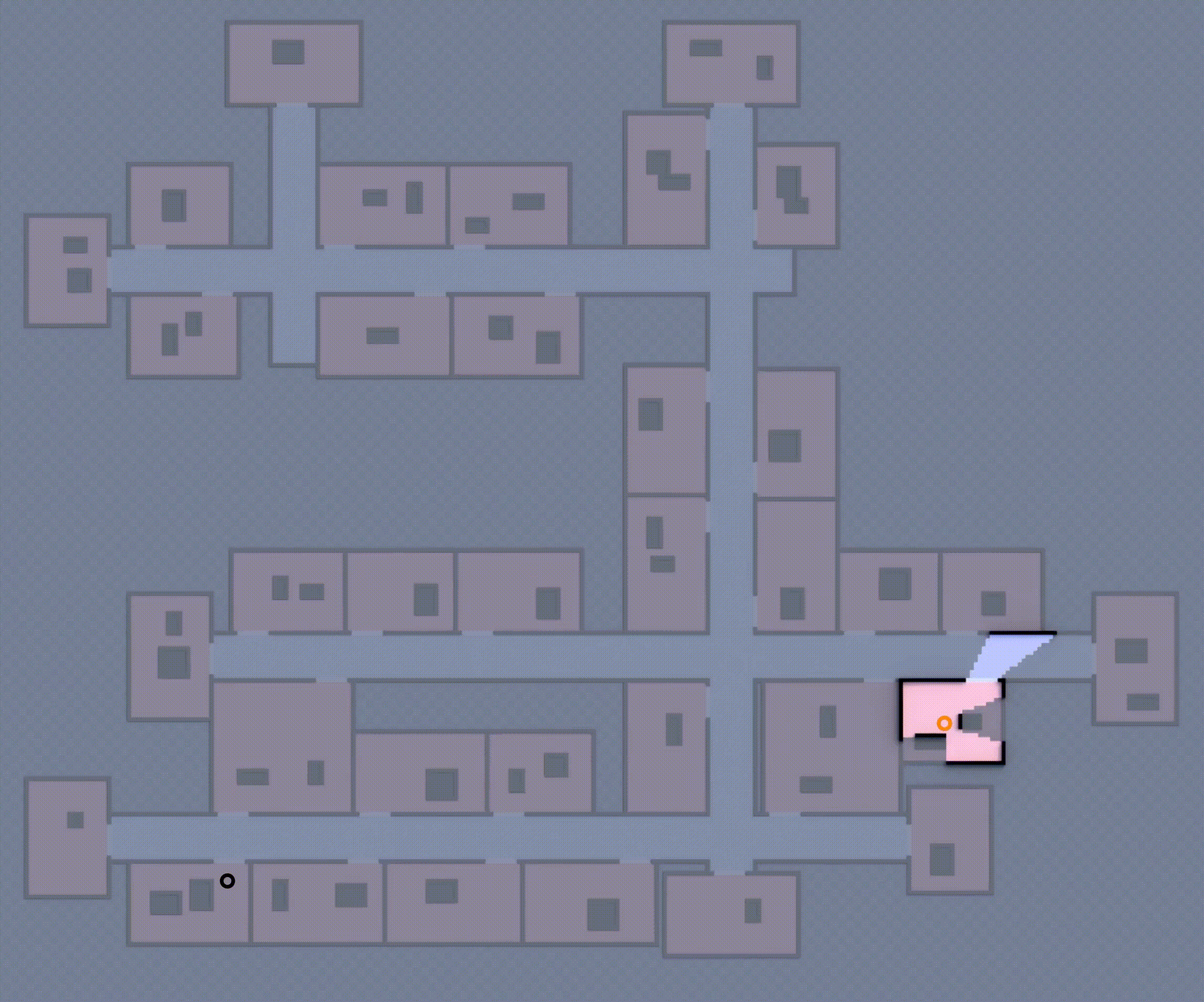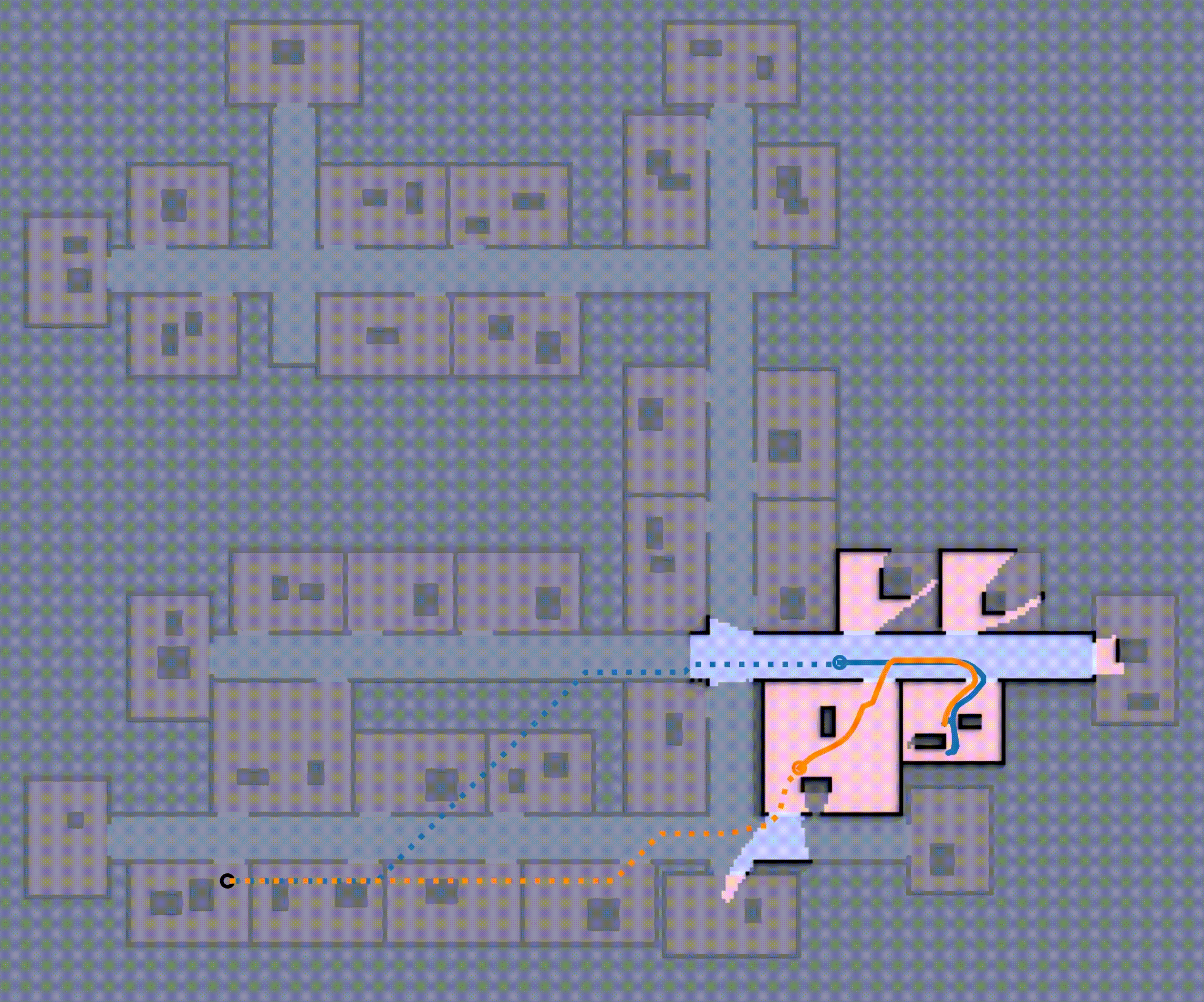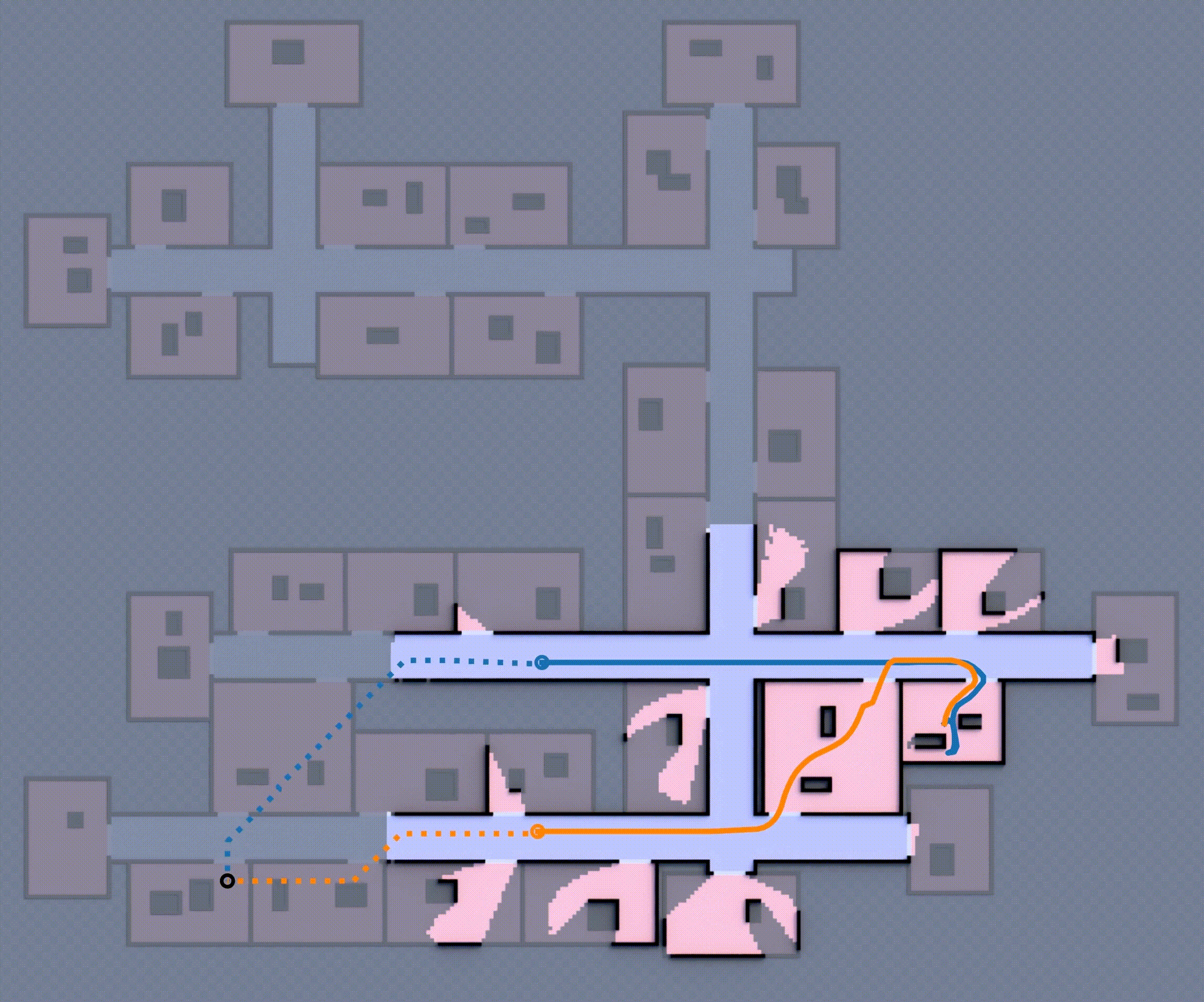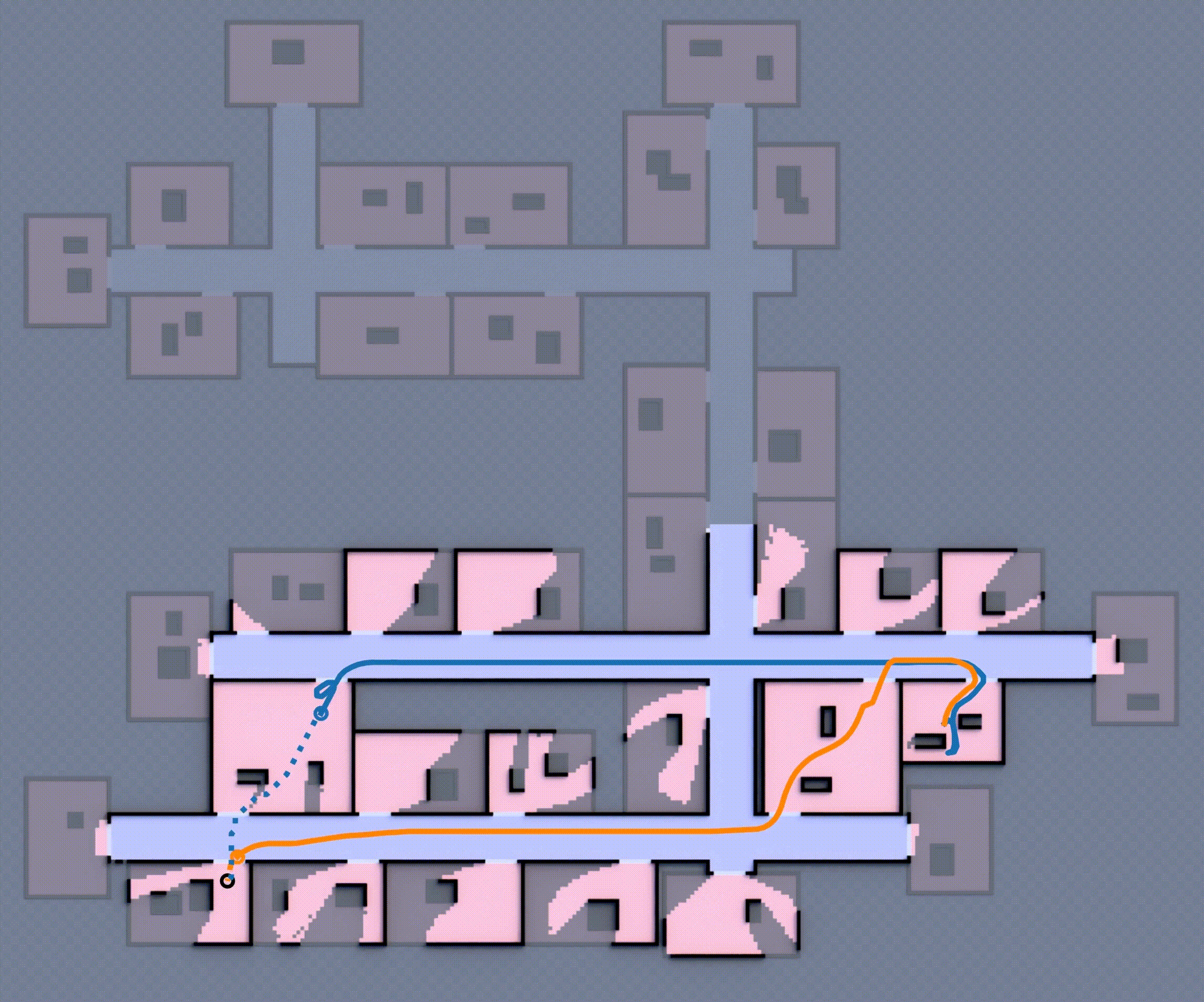
If you want to learn more about the multi-robot state and action abstraction, the planning process, and how the learned model is trained, check out the paper (Khanal & Stein, 2023).
Reference
- . "Learning Augmented, Multi-Robot Long-Horizon Navigation in Partially Mapped Environments". IEEE International Conference on Robotics and Automation (ICRA), 2023.